The Stacks, explained
These poems are being categorized using a process known as latent semantic analysis, which just means I'm using a computer to try and determine a relationship between documents. The process I use is as follows:
First I vectorize the set of documents using sklearn's tf-idf vectorizer. This essentially means I break each poem down into a list of which words appear, and how frequently they appear in that poem compared to how many poems they appear in total.
Due to the small sample size, I also use the nltk lemmatizer before vectorizing to encourage more word overlap. The lemmatizer consolidates some similar words to appear in the dataset as the same word. In practice this mostly means words stop being plural, but it also standardizes some verbs, like "rushes" becoming "rush".
The next step is applying singular value decomposition, which is a type of dimensionality reduction. The actual calculation is a bunch of matrix bullshit, but the goal is to identify two vectors that cover the largest amount of variation in this dataset, and assigns those as the x and y coordinates in a grid.
Below is a drawing to try and explain what it means to take the "most significant" vectors in the dataset and make those your x and y coordinates. Notice how the blue line drawn onto the first graph follows the direction where the dataset is the most stretched out. The other line is perpendicular to the first one, because if they had any movement in the same direction, it would be redundant.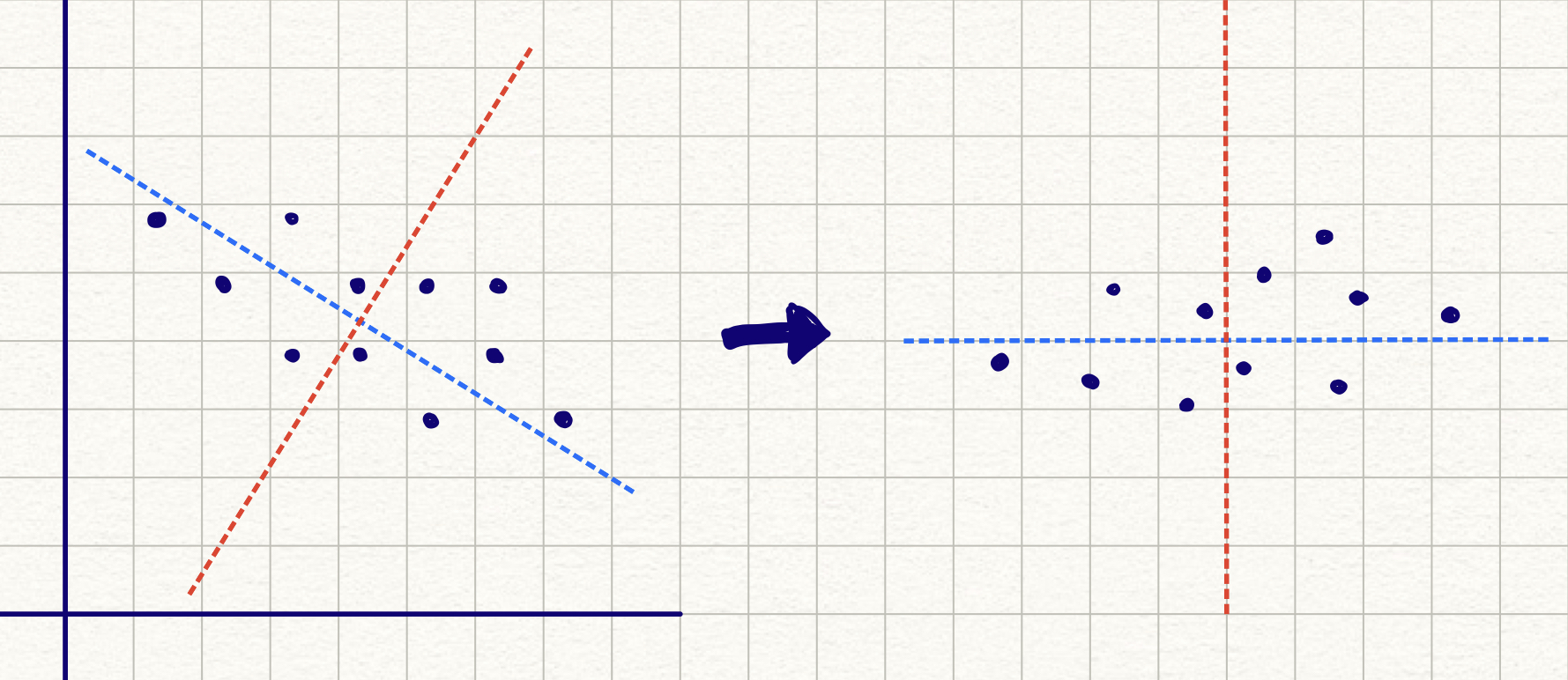
Remember that although that image is in two dimensions to begin with for ease of visualization, the actual dataset has around 1000 dimensions to start, each representing a unique word. Similar to how the vectors chosen have movement in both the x and y axis to start, the vectors that are chosen by SVD don't represent single words, but combinations of different words in proportion to each other.